When your organization’s data grows and diversifies, geospatial analysis faces two key challenges: efficient data integration and scalability. ArcGIS GeoAnalytics Engine – a cloud-native library with a comprehensive set of spatial functions and tools – addresses these challenges by moving geoanalytics workflows directly to where your data resides – in data lakes, data warehouses, or ArcGIS. GeoAnalytics Engine is fully integrated with Apache Spark, thus can process and analyze spatial datasets at scale with advanced geospatial operations including space-time pattern mining, track data analysis, geocoding, reverse geocoding, network analysis, and spatial modeling.
Why Integrate ArcGIS GeoAnalytics Engine with AWS Glue?
Accessing and preparing large, diverse datasets from various sources can be painstaking and time-consuming – that is where AWS Glue comes in. AWS Glue is a serverless data integration service designed to simplify the discovery, preparation, transfer, and integration of your datasets from various sources for analytics, machine learning, and application development. It automatically scales compute resources, supports Spark and PySpark jobs, and runs your extract, transform, and load (ETL) tasks, making it more efficient to clean, organize, and securely move datasets between sources like Amazon S3 and Redshift.
GeoAnalytics Engine in AWS Glue offers your organization a streamlined geospatial data integration with both data lakes and ArcGIS. With that, you are now better equipped to orchestrate your ETL pipeline that can run highly scalable geospatial analysis both on-demand and on-schedule.
Note that while ArcGIS GeoAnalytics Engine is certified and tested with AWS EMR, it is not specifically tested with AWS Glue. At this time, network analysis and geocoding tools are not supported in Glue.
Getting Started in AWS Glue
Let’s showcase how you can get up and running with GeoAnalytics Engine in AWS Glue Studio to run geoanalytics workflows interactively or on schedule. First, follow the guideline here to download ArcGIS GeoAnalytics Engine distribution. Next, sign in to your AWS Management Console and upload those distribution files to your S3 bucket. After that navigate to AWS Glue Studio and start or upload a Notebook with an appropriate IAM role so that it has permissions for data access and ETL job.
IAM Role Configuration for Secure Access:
- Create a specific IAM role for Glue jobs
- Apply least privilege principle
- Required permissions:
- secretsmanager:GetSecretValue
- s3:GetObject for GeoAnalytics Engine files
- s3:PutObject for output locations

Configure Spark Environment
Let’s start with an empty notebook. In the notebook cell, first, configure the compute resources on the backend including the Glue version, worker type and number of workers, using the following commands:
%glue_version x.x %number_of_workers 5 %worker_type G.1X
For more information about scaling your AWS Glue for Apache Spark jobs, check out this blog post.
Import and Configure GeoAnalytics Engine Distribution
Given that we have already uploaded GeoAnalytics Engine installation files to S3, next, we import those necessary JARs and Python Wheel (.whl) files to the Spark environment, using the following commands:
%extra_jars s3://ga-engine/Install_GeoAnalytics/geoanalytics_2.12-1.6.0.jar %extra_py_files s3://ga-engine/Install_GeoAnalytics/geoanalytics-1.6.0-py3-none-any.whl
Now, you have to set several Spark properties, as shown below, before a Spark context is created.
%%configure
{ "--conf": "spark.serializer=org.apache.spark.serializer.KryoSerializer --conf spark.kryo.registrator=com.esri.geoanalytics.KryoRegistrator --conf spark.plugins=com.esri.geoanalytics.Plugin"}
Once these properties are set, you will be able to import geoanalytics in your Spark session and authorize the module using a username and password, a license file, or an API key. Next, initialize a Glue session:
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from awsglue.context import GlueContext from awsglue.job import Job from pyspark.context import SparkContext sc = SparkContext.getOrCreate() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext)
Import geoanalytics library and authenticate
We will retrieve a JSON credentials file stored in our S3 bucket and then use those credentials to authenticate the geoanalytics module.
import geoanalytics import json import boto3# Initialize S3 client s3_client = boto3.client('s3') bucket_name = 'your-s3-bucket-name' file_key = 'gae_credentials.json' response = s3_client.get_object(Bucket=bucket_name, Key=file_key) creds_json = json.loads(response['Body'].read().decode('utf-8')) # Authenticate geoanalytics.auth(username = creds_json['geoanalytics']['username'], \ password = creds_json['geoanalytics']['password'])
Alternatively, if you want to authenticate the module using a license file stored in your S3 bucket:
geoanalytics.auth(license_file="s3://your-secure-bucket/path/to/license.ecp")
You can also use an API key for an active GeoAnalytics Engine subscription – see here.
Use Case: Analyzing Real-Time Flight Data
Let’s take a look at how you can use AWS Glue and ArcGIS GeoAnalytics Engine together to tackle your analytics problems. We’ll do this with an example exploring real-time streaming of flight data.
Real-time streaming data needs to be processed instantly or on schedule for optimal decision-making, efficiency, cost savings, ensuring safety and security. FlightAware is a leading provider of real-time flight tracking data. Thanks to the integration of ArcGIS Velocity and FlightAware, organizations can now bring live, global aircraft positions (per second) directly into ArcGIS Online as feature layer, as well as into big data storages like S3 as formats like parquet.
Let’s read FlightAware’s flight position data (over 200 million records) using data exported periodically from ArcGIS Velocity to our S3 bucket. We read this into a Spark DataFrame in a Glue notebook. Using GeoAnalytics Engine’s ST-like SQL functions, create point geometries and filter the data to include only flights inbound to Ronald Reagan Washington National Airport.
path = "s3://ga-engine/Datasets/FlightAware/feed/*.parquet"
df = spark.read.format("parquet").load(path)
df_dca = (df
.withColumn("point", ST.transform(ST.point("lon", "lat", 4326), 8857))
.filter(df.dest == "KDCA")
.filter("point IS NOT NULL")
.select("id", "aircrafttype", "orig", "dest", "ident", "heading", "point", "clock", "alt"))
Next, using ReconstructTracks tool, connect all time-sequential points for each flight into tracks and summarize records within each track.
from geoanalytics.tools import ReconstructTracks
tracks = ReconstructTracks() \
.setTrackFields("id") \
.setDistanceMethod(distance_method="Planar") \
.addSummaryField(summary_field="alt", statistic="Min") \
.addSummaryField(summary_field="alt", statistic="Max") \
.addSummaryField(summary_field="alt", statistic="Mean",
alias="avg_alt") \
.run(dataframe=df1) \
.show(5)

Export flight tracks to ArcGIS Online and visualize
You can export the tracks DataFrame to ArcGIS Online as a hosted feature layer and create a flight track app to visually explore durations of each flight (Figure 1). These near-real-time flight tracks can be further analyzed alongside weather data for hazard detection and alerting. In the event of an aircraft incident or near-miss, investigators can reconstruct flight paths to gain insights into the circumstances surrounding the event.
tracks.write.format("feature-service") \
.option("gis", "myGIS") \
.option("serviceName", "flightAware_DCA_Tracks") \
.option("layerName", "flightAware_DCA_Tracks") \
.save()
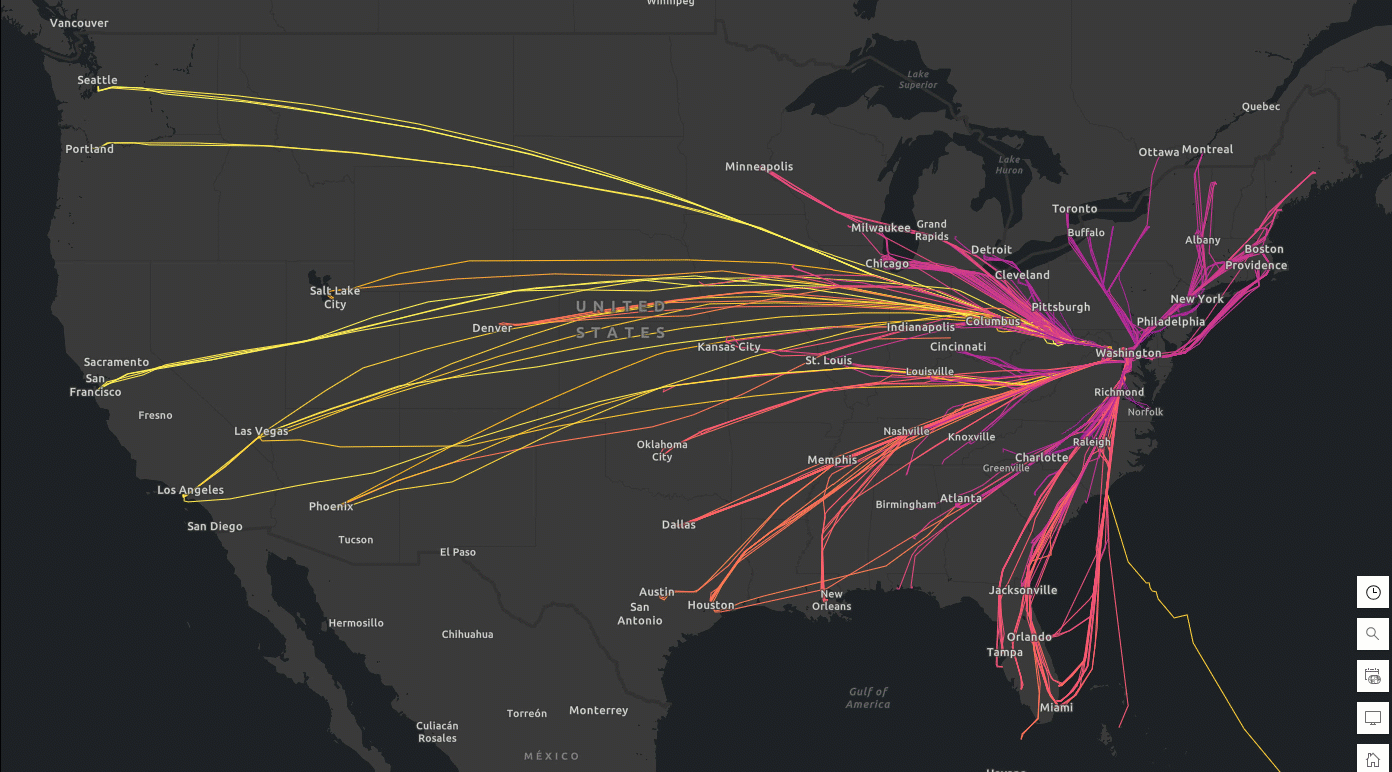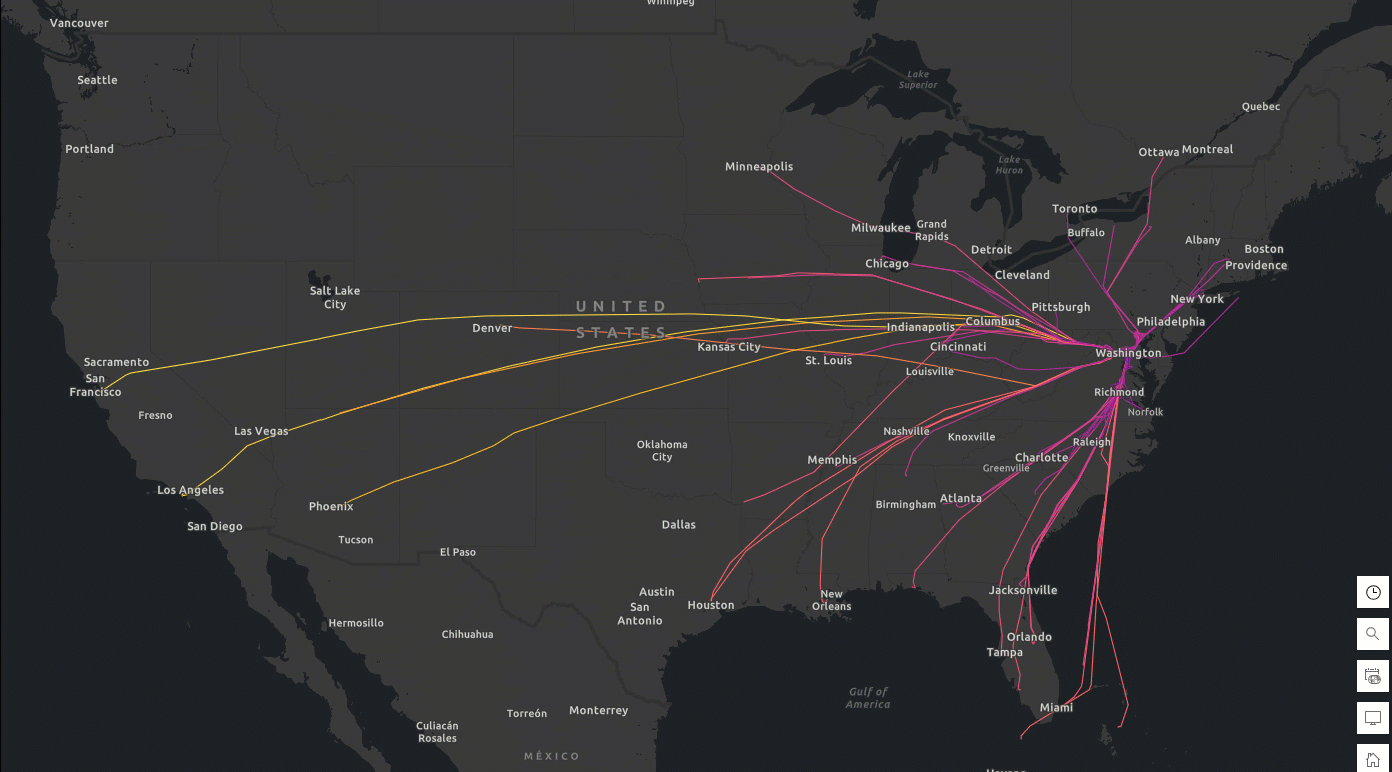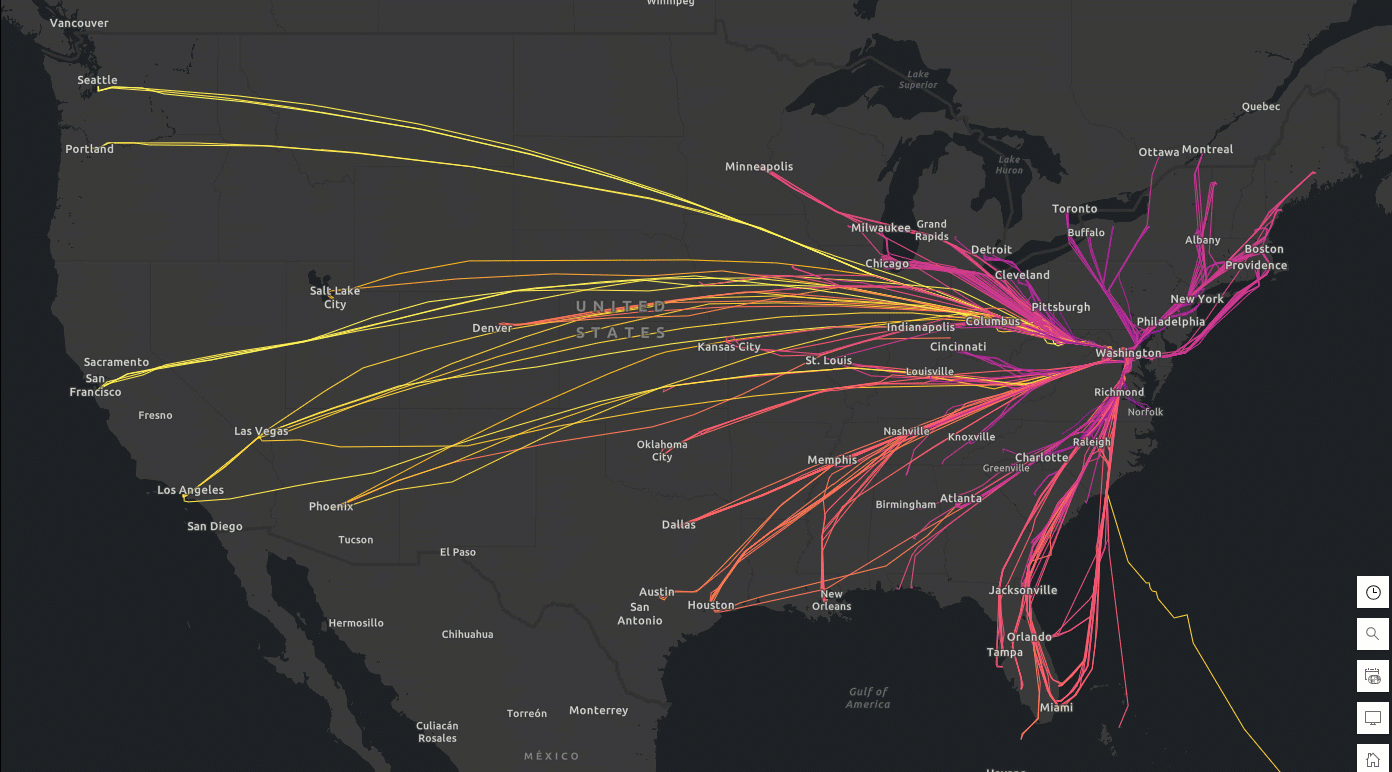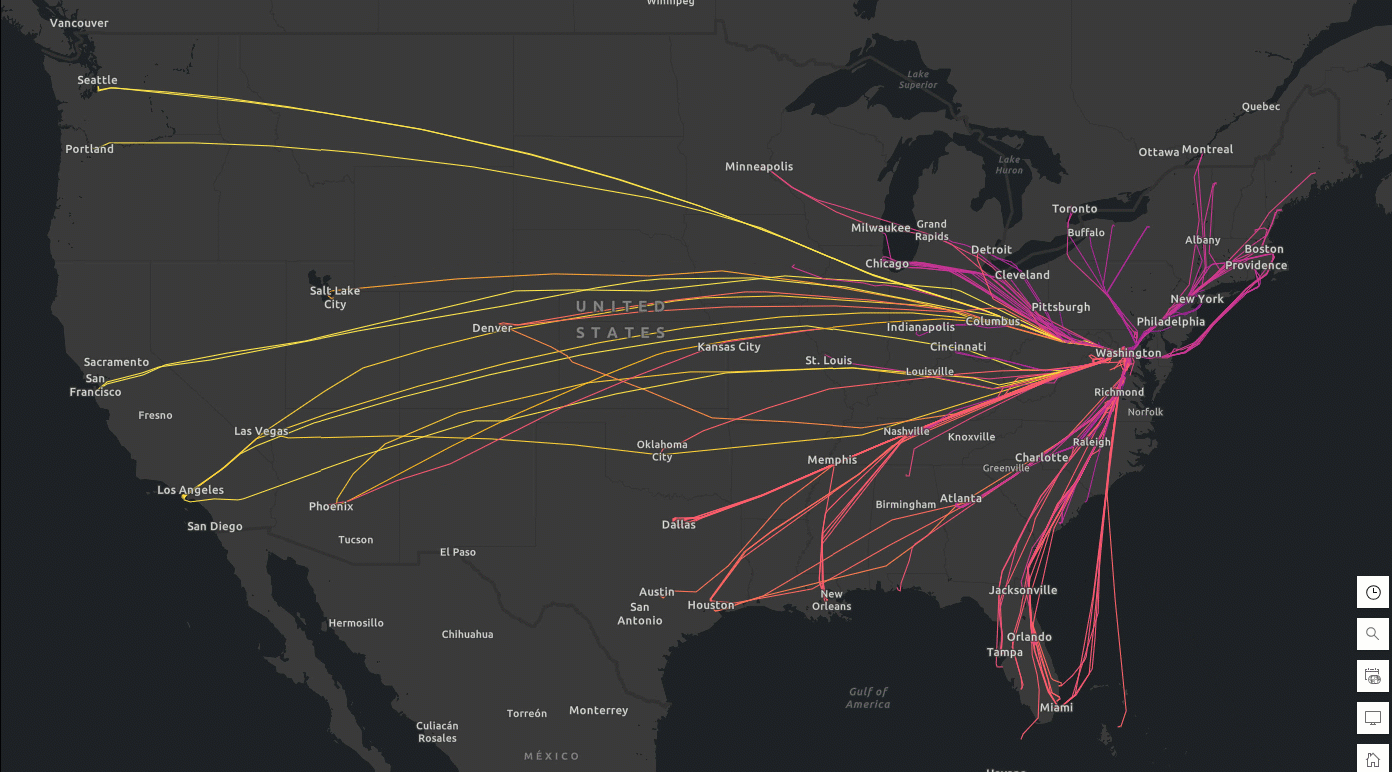
Figure 1. Daily tracks and duration of flights (Feb 6-9, 2025) to Ronald Reagan Washington National Airport (Code: DCA). Data source: FlightAware
By analyzing real-time flight tracking and historical flight data, geo-enriched with other context-aware information such as weather events, and gaining predictive insights, companies can identify problem areas such as delays, flight incidents, route inefficiencies, or recurring issues with specific airports or airlines. These insights enable proactive decision-making, optimizing operations, improving customer experiences, streamlining supply chain management, and more.
Automating the Workflow with AWS Glue Triggers
As your streaming and historical datasets continuously flow in, you can execute this notebook workflow on-demand and also based on a schedule using AWS Glue triggers. This allows for easy and reliable time-based job scheduling (e.g., every hour, day, week, or month), making it more efficient to automate data workflows and reducing the need for manual oversight or external scheduling systems.
Conclusion: Unlocking Scalable Geospatial Intelligence
This blog offers a step-by-step guide on setting up and executing ArcGIS GeoAnalytics Engine workflows in AWS Glue, emphasizing the advantages of utilizing both for big data ETL and spatial analytics jobs via an aviation industry use case using FlightAware Firehose℠ Flight Data Feed.
By leveraging AWS Glue’s fully managed, serverless environment, and the Apache Spark-based functionalities of GeoAnalytics Engine, you can process and analyze large spatial datasets without the need for infrastructure management. Whether you’re working with real-time streaming data, very large historical datasets spanning years to decades, or complex geospatial operations, this integrated solution streamlines your ETL processes, improves speed, all while providing robust tools for advanced spatial analysis.
We hope this guide inspires you to explore how GeoAnalytics Engine and AWS Glue can address your geospatial data challenges. For more details, check out the official documentation on GeoAnalytics Engine and AWS Glue. We’d love to hear how you’re using these tools in your own projects and workflows—feel free to share your experiences with us!
WARNING: The example code in this blog demonstrates concepts only. Production deployments should undergo comprehensive security reviews and follow your organizations security policies and compliance requirements.


Article Discussion: